

Tracking and improving incident management is crucial in today’s interconnected world where technical disruptions can have significant consequences. System downtime can cost companies an average of $300,000 per hour in lost revenue, productivity, and maintenance. Major outages can lead to even greater losses, impacting customer satisfaction and potentially driving business to competitors. Therefore, it’s essential for teams to track incident management Key Performance Indicators (KPIs) to effectively detect, diagnose, fix, and prevent incidents.
While web and software incidents offer the advantage of capturing extensive data for analysis, the sheer volume of information can sometimes obscure the real issues. This article will guide you through selecting the most relevant KPIs for your incident management program. After this overview, you may want to deep dive into specific areas, like understanding more about KPI meaning in food industry.
The Importance of Incident KPIs
KPIs are metrics that measure progress towards specific business goals. In incident management, these metrics can include the number of incidents, average resolution time, or time between incidents. Tracking these KPIs allows you to:
- Identify and diagnose problems: Pinpoint bottlenecks in processes and systems.
- Set benchmarks and goals: Establish realistic targets for your team.
- Spark deeper investigation: Raise critical questions about performance and efficiency.
For instance, if your goal is to resolve all incidents within 30 minutes but your team averages 45 minutes, KPIs can help you determine where the problem lies. Is the alert system slow? Is the diagnostic process inefficient? Are specific teams underperforming?
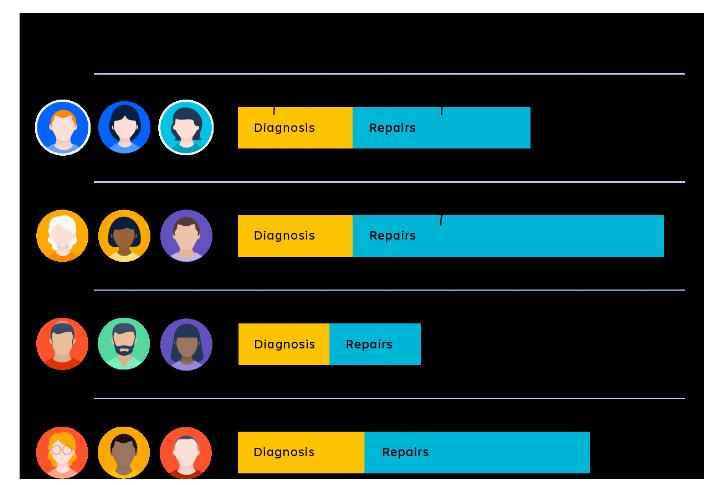 Four teams with differing mean time to respond (MTTR) measurements.
Four teams with differing mean time to respond (MTTR) measurements.
Key Incident Management KPIs to Track
Here are some of the most common incident management KPIs:
Alerts Created
This metric tracks the number of alerts generated by your alerting tool within a specific timeframe. Significant increases, decreases, or upward trends warrant further investigation to understand their root causes and how your team is responding.
Incidents Over Time
This KPI measures the average number of incidents over different periods (weekly, monthly, quarterly, etc.). Analyzing trends helps assess whether the incident frequency is acceptable and identify potential problems requiring action.
MTBF (Mean Time Between Failures)
MTBF represents the average time between repairable failures of a technology product, providing insights into availability and reliability. A lower than desired MTBF indicates the need to investigate the causes of frequent failures and implement preventive measures.
MTTA (Mean Time to Acknowledge)
MTTA measures the average time between a system alert and its acknowledgment by a team member. This KPI reflects team responsiveness, highlighting potential issues like overburdened teams, unclear responsibilities, or distractions.
MTTD (Mean Time to Detect)
MTTD is the average time it takes to discover an issue, often used in cybersecurity to track the efficiency of breach detection. Significant changes in this metric require further investigation. Consider reviewing your team’s understanding of core processes, like knowing the difference between efficiency and effectiveness.
MTTR (Mean Time to Resolve)
MTTR, encompassing Mean Time to Repair, Resolve, Respond, or Recovery, ideally measures the total time from problem detection to its complete resolution, including preventative measures. A high MTTR necessitates deeper analysis of the resolution process.
On-Call Time
Tracking on-call time for employees and contractors ensures fair workload distribution and prevents burnout. This data helps identify potential imbalances and optimize on-call scheduling.
SLA (Service Level Agreement)
SLAs define agreed-upon metrics like uptime and responsiveness between a provider and client. Tracking SLA adherence ensures contractual obligations are met and helps identify areas needing improvement.
SLO (Service Level Objective)
SLOs, specific metrics within an SLA (e.g., uptime), help monitor performance against defined targets. Tracking SLOs ensures compliance with service level commitments.
Timestamps (Timeline)
While not a traditional metric, timestamps provide crucial information about events during an incident, enabling the creation of detailed timelines for post-incident analysis and process improvement.
Uptime
Uptime, the percentage of time systems are operational, is crucial for meeting customer expectations. While 100% uptime is rarely achievable, striving for high availability (99.9% or higher) is standard practice.
Beyond the Numbers: The Importance of Context
While KPIs provide valuable data, they shouldn’t be interpreted in isolation. Understanding the context behind the numbers is crucial for effective incident management. Two incidents with the same MTTR might have vastly different complexities and require distinct approaches. Therefore, qualitative insights from team experience and incident specifics are essential for comprehensive analysis and meaningful improvement. For example, consider exploring strategies for boosting employee morale. A motivated team is more likely to achieve positive KPI results.
KPIs are a starting point, a diagnostic tool guiding deeper investigation and ultimately leading to more effective incident management practices. They help identify areas for improvement, but true optimization requires a holistic approach that combines data analysis with qualitative insights and a focus on continuous learning.